Understanding Attention Mechanisms
A Deep Dive into Query, Key, and Value Vectors

Introduction
The attention mechanism, introduced in the landmark paper "Attention Is All You Need," revolutionized natural language processing and laid the foundation for modern Large Language Models (LLMs). This article explores the key concepts behind attention mechanisms and their implementation.
Background
Before transformers, neural networks like RNNs and LSTMs struggled with understanding long-range dependencies in text. The attention mechanism solved this limitation by introducing a novel approach to process sequential data.
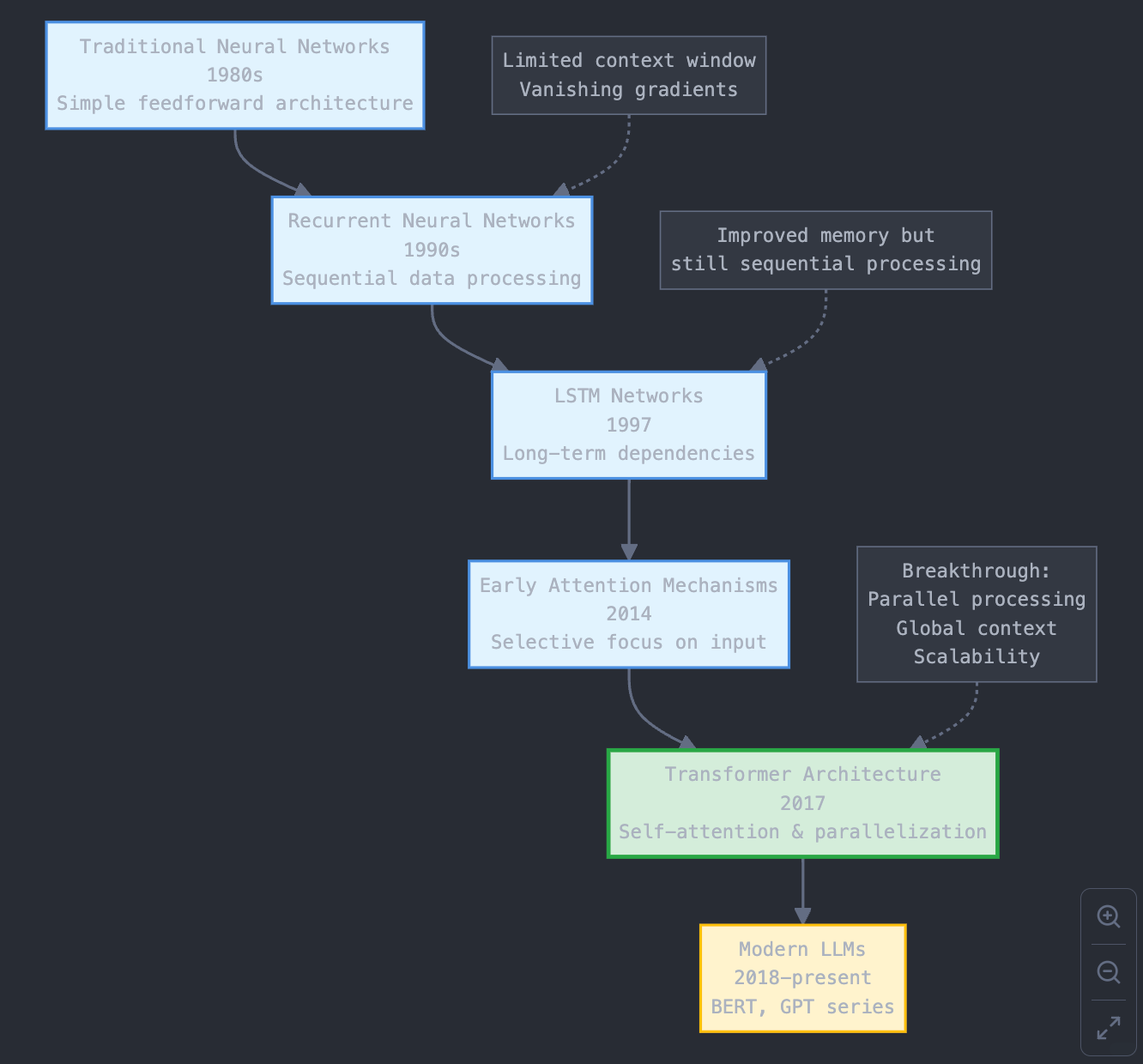
Imagine you're reading a long news article. To understand the end, you need to remember what was discussed at the beginning. RNNs have a hard time with this because they process the text sequentially, and information from the beginning can get 'lost' along the way. So Transformers, and specifically the attention mechanism, solve this by allowing the model to directly look at “all” parts of the sentence at once, paying attention to the most important words.
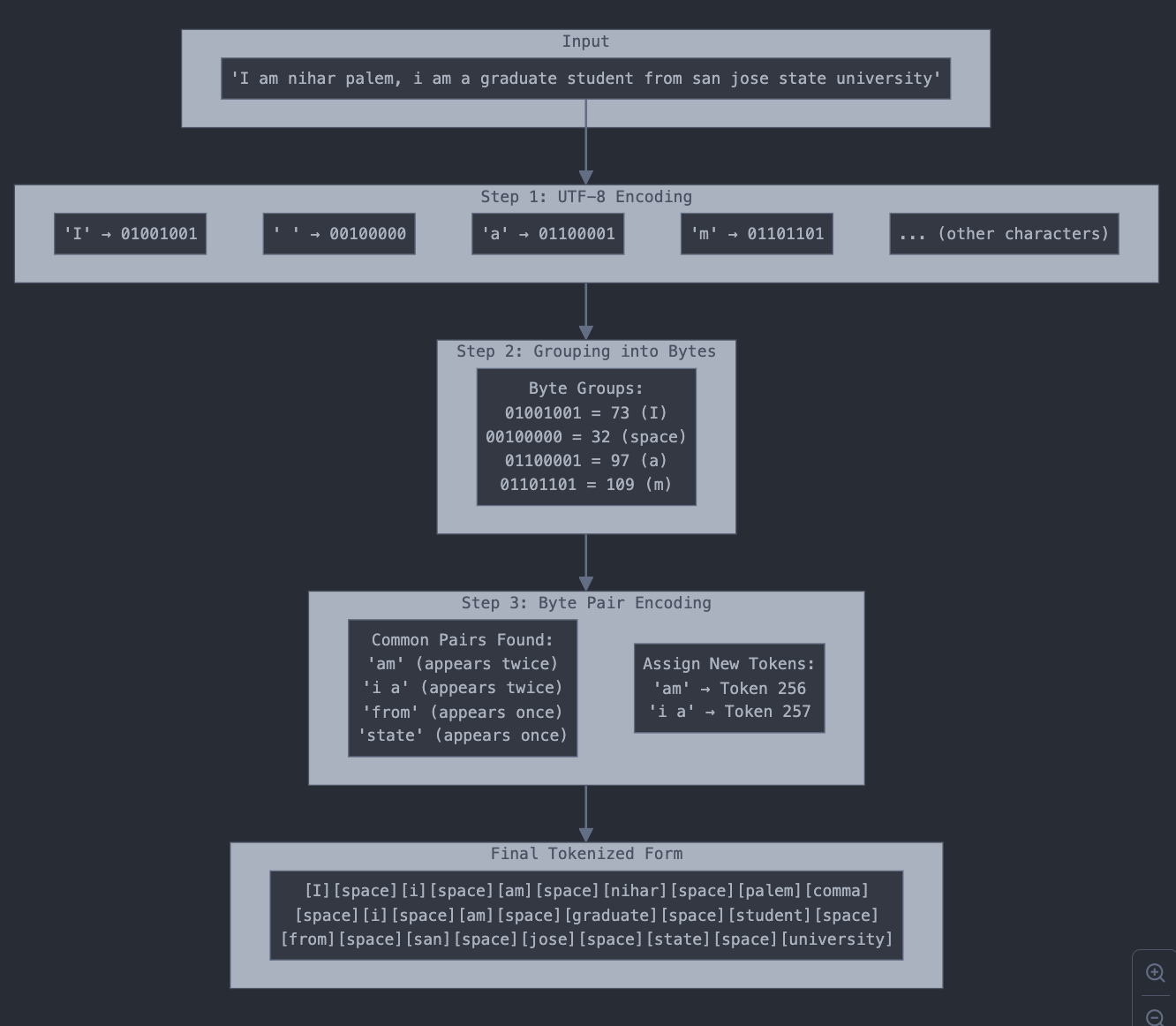
For any model to parse text it needs to be converted as tokens, the following example of byte pair encoding:
Consider this example sentence:
"I am nihar palem, i am a graduate student from san jose state university"
The processing of text involves multiple steps:
Converting strings to bits
Bits to byte
Byte-pair encoding
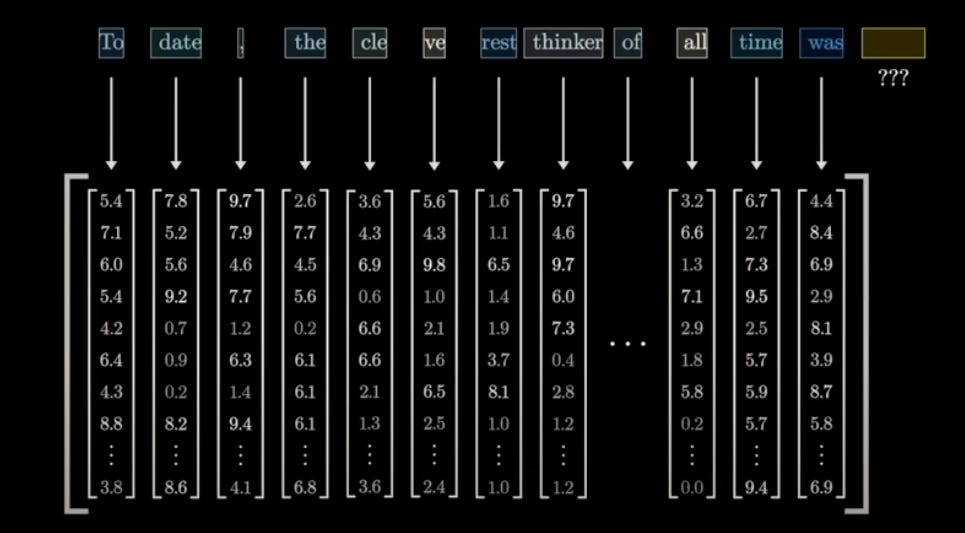
Generating embedding vectors
To try how tokenizer works check this: Tiktokenizer
Next after generate tokens we send them to attention block in which,
Core Components of Attention
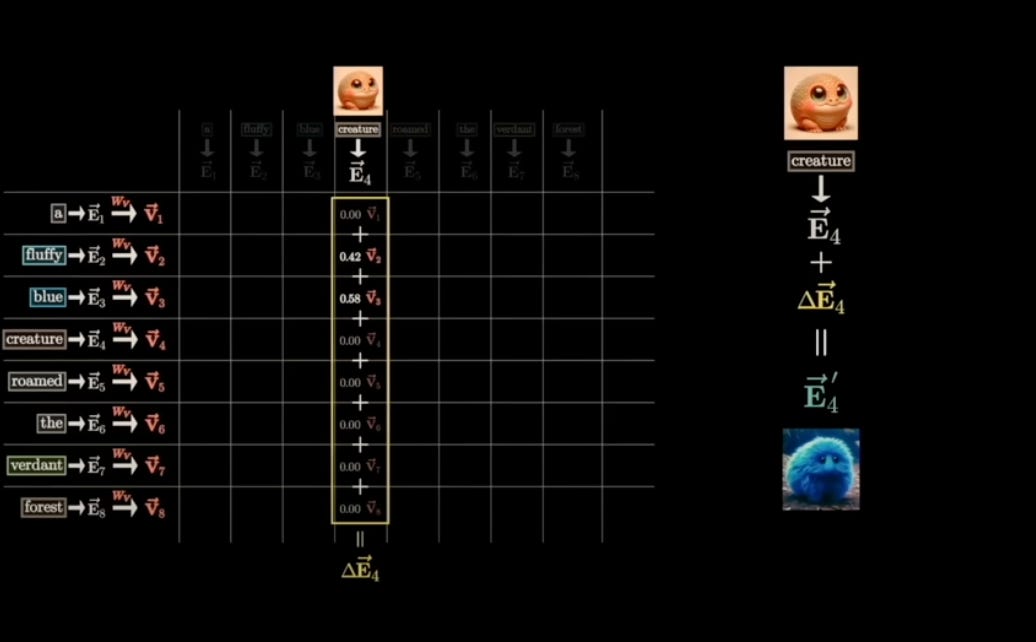
Q: "What information am I looking for?"
K: "What information do I have in this word?"
V: "The actual content of this word."
“We use the Query vector of one word and the Key vector of another word to calculate their attention score. The Value vector is then used to extract the actual content from the important words.”
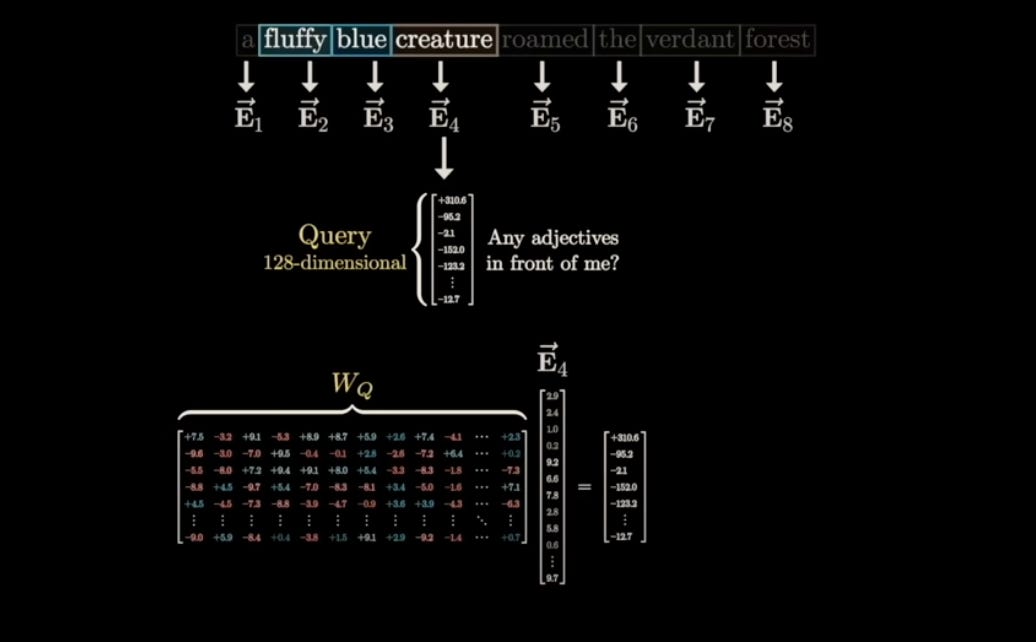
Query Vector (Q)
The Query vector represents the question being asked by a particular word. It's like asking, 'What information am I, this word, looking for from other words in the sentence?
The query vector is generated by multiplying the embedding vector with a learned matrix. It essentially asks questions about the relationships between different parts of the text.
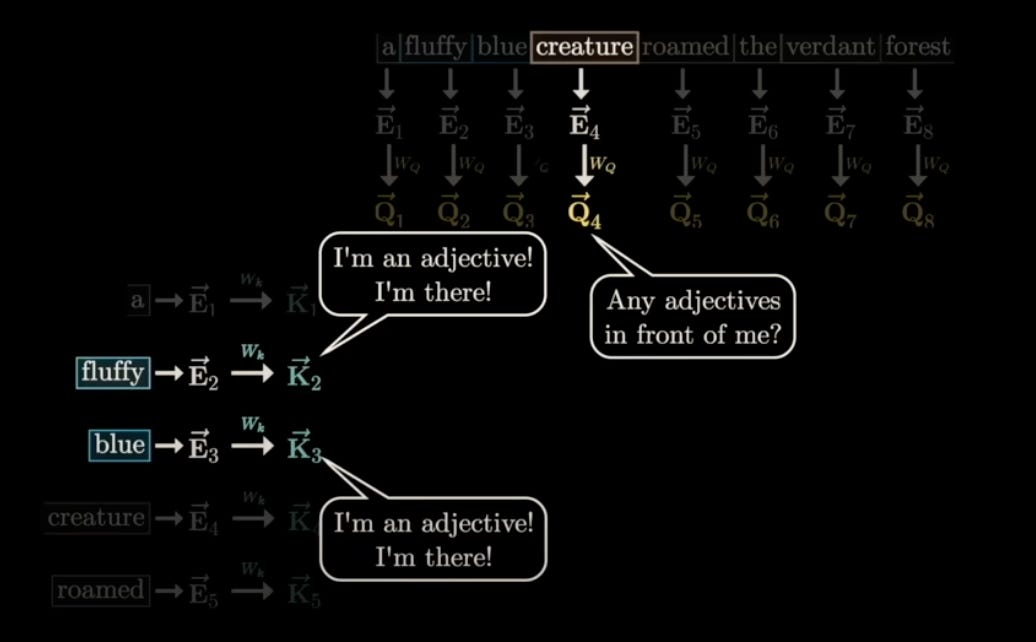
Key Vector (K)
The Key vector represents the information that a particular word contains. It's like saying, 'Here's what I, this word, have to offer to other words in the sentence.'
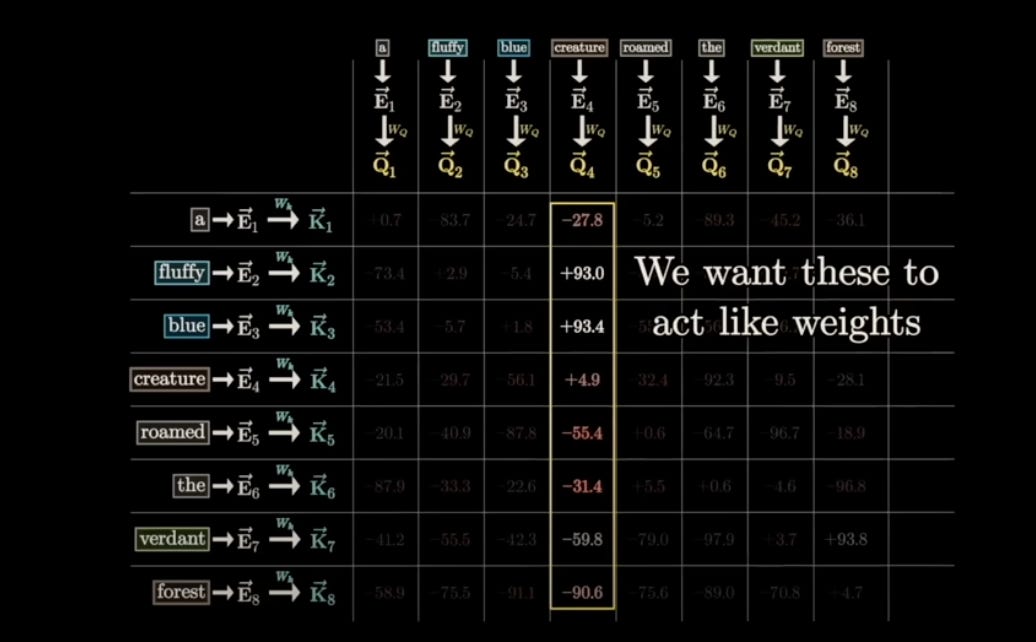
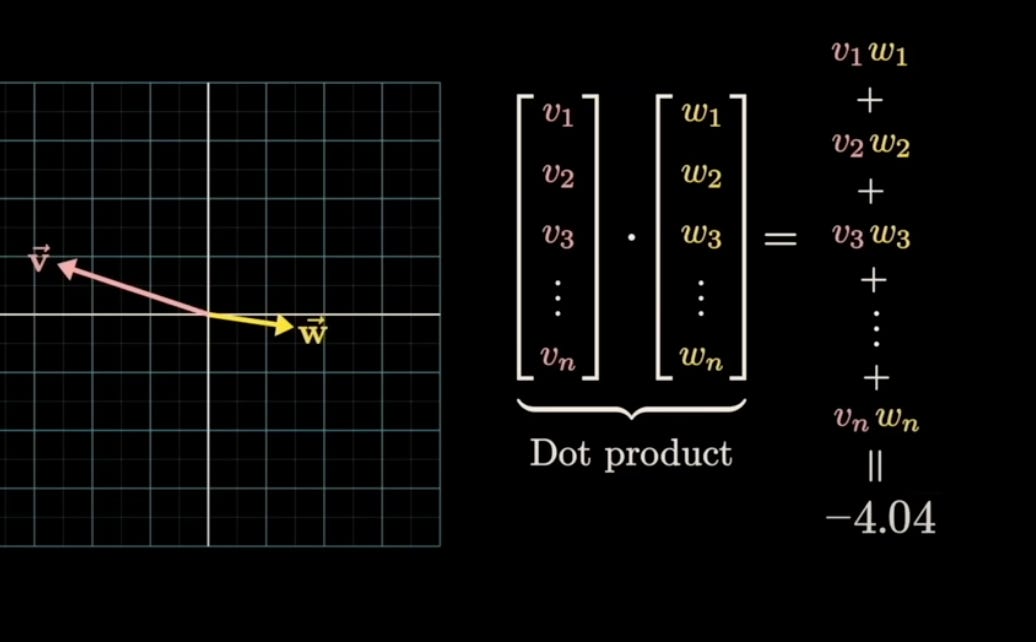
The key vector works in conjunction with the query vector. Both Q and K are trained in the same pattern and align in the same dimensional space (typically 128D). Their interaction is measured through dot products:
- Positive values indicate similarity
- Negative values indicate difference
We then apply softmax to them the make fall in range between 0 and 1.

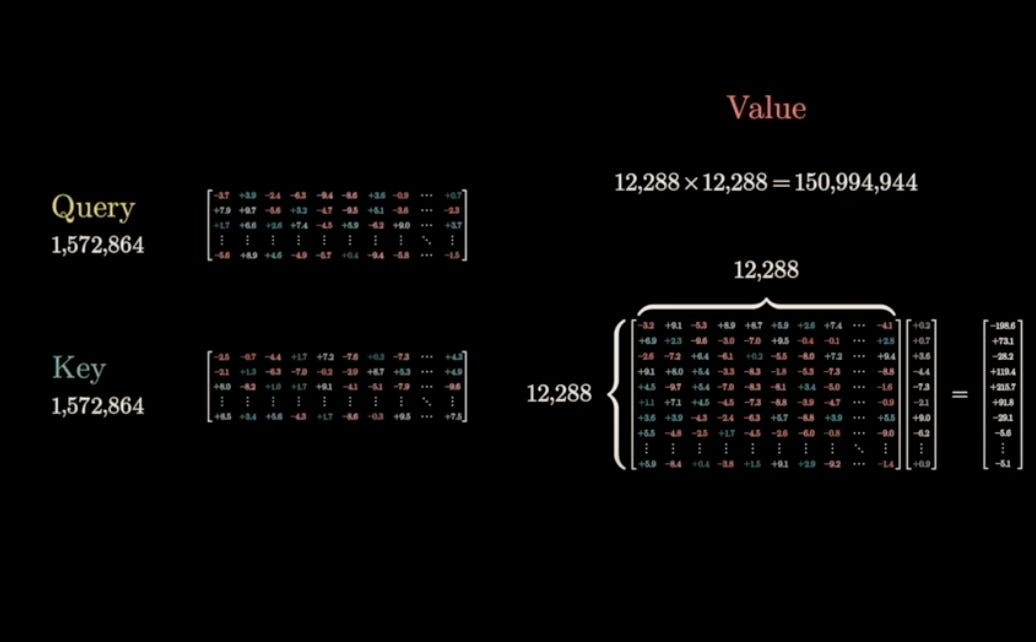
Value Vector (V)
The Value vector represents the actual content of the word. It's the information that will be used if another word finds this word relevant.
They are generated from the embeddings through raw embeddings with matrix multiplication. Later they are sent to QK (masked attention)+ this v vector gives the context aware outputs.
The value vector is derived through the formula:
V = X · W^V
Where:
- X is the input embedding
- W^V is a trainable matrix
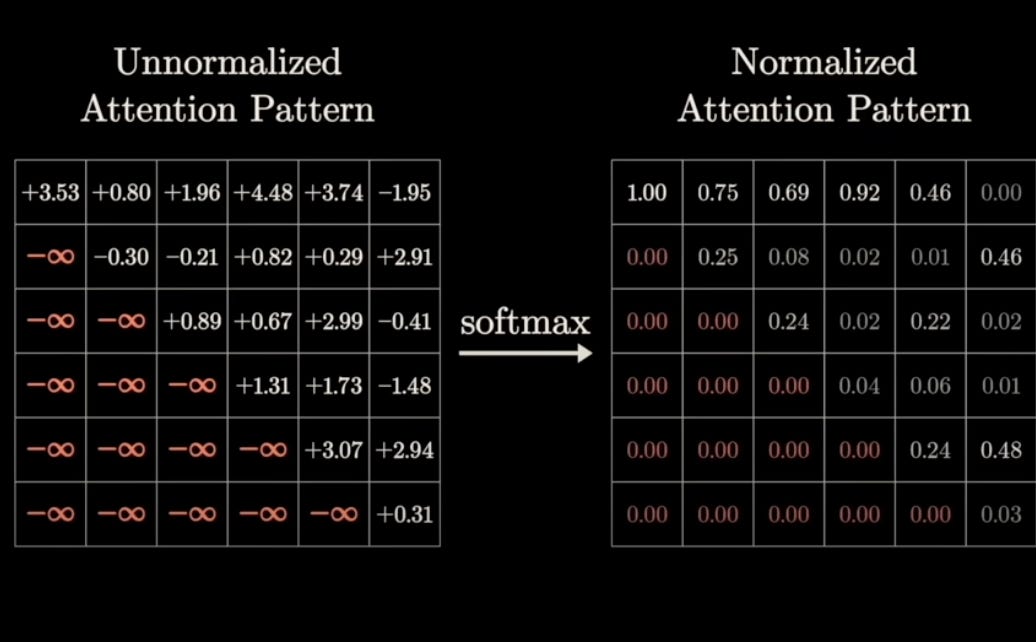
Masked Attention Pattern
In tasks like generating text (e.g., writing a story), we want the model to predict the next word without peeking at the words that come later in the sequence. This is like trying to guess the next word in a sentence without seeing it. To prevent the model from 'cheating' and looking ahead, we use masking.
1. Values after the current position are set to negative infinity
2. When softmax is applied, these values become zero
3. This creates a causal attention pattern
Attention Computation Process
1. Computing Attention Scores
The attention score is calculated using:
Attention Weight = softmax(QK^T / sqrt(d_k))
QK^T: "This is the dot product of the Query and Key vectors. It measures how similar they are. A higher score means the words are more related."
sqrt(d_k): "We divide by the square root of d_k (the dimension of the Key vector) to stabilize the training process."
softmax: "Softmax converts these scores into probabilities between 0 and 1. This makes it easier to compare the importance of different words."
2. Weighted Sum Calculation
Finally, we take a weighted sum of the Value vectors, using the attention scores as weights. This gives us a context-aware representation of the input text
Output = ∑(Attention Weight_i · v_i)
This formula means that each Value vector is multiplied by its corresponding attention weight, and then all the weighted Value vectors are added together. This creates a final output that represents the meaning of the input text, taking into account the relationships between the different words.