

Introduction
I was curious as current LLM’s are doing great doing in understanding sequence of texts for predicting or answering the questions, But what if we give it a big book of say 10000 pages to read considering an average of tokens 100,000+, Given this large context LLM can hallucinate because of its limit on context window which is basically the size of the Q,K,V a model can take. So, curiously digging on how to handle long reasoning i found a paper called “Large Memory Models”.
This paper talks about handling the long context reasoning by adding a memory bank near attention layer and performing the same way how an LSTM handles sequence of data (gating mechanism)
PS: They never mentioned LSTM in their paper but as the attention and memory bank arch looks similar to LSTM drawing comparison with it (LSTM)
for example, refer the arch of LSTM below and LMM (Large Memory models)

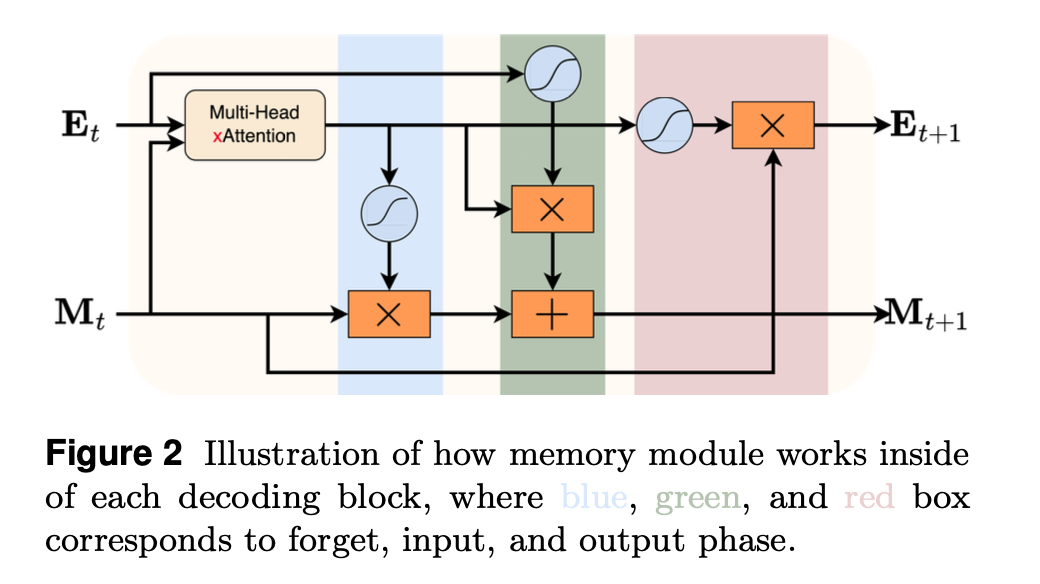
Architecture
The architecture of the LMM near a attention layer looks like this
As we know that the attention is between 3 matrices Q (query) ,K (key) ,V (value) and we apply them from the same input data and we update accordingly
For understanding of what is about the Q,K,V (check this article)
Coming back to the LMM, here we we Create/ Update the Query (Q) matrix from the data (training data) and the Key (K) and Value (V) matrices are taken/ Updated to the memory bank
Memory bank: Each memory bank has N slots and each slot has a hidden dimension (identity matrix) details of these are mentioned later in the article
Working of Memory module
The memory module works in 2 stages:
Stage 1: Memory information flow
As said earlier the Q,K,V matrices are taken from data (Q) and memory bank (K,V)
The below equation shows how the matrices are being calculated
Q (query): It takes embeddings from tokens (data) and does matrix multiplication with the weights matrix
K (key): It takes the embeddings or values for the Memory bank and does the same matrix multiplication with its weight matrix
V (value): It takes the embeddings or values for the Memory bank and does the same matrix multiplication with its weight matrix
Simple analogy:
Think of like for the question (query) raised based on data search for information from the memory book (key and value)
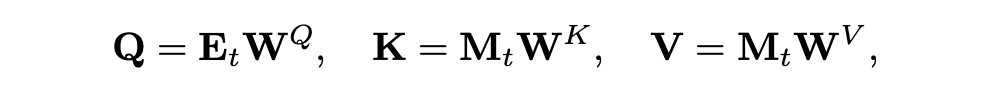
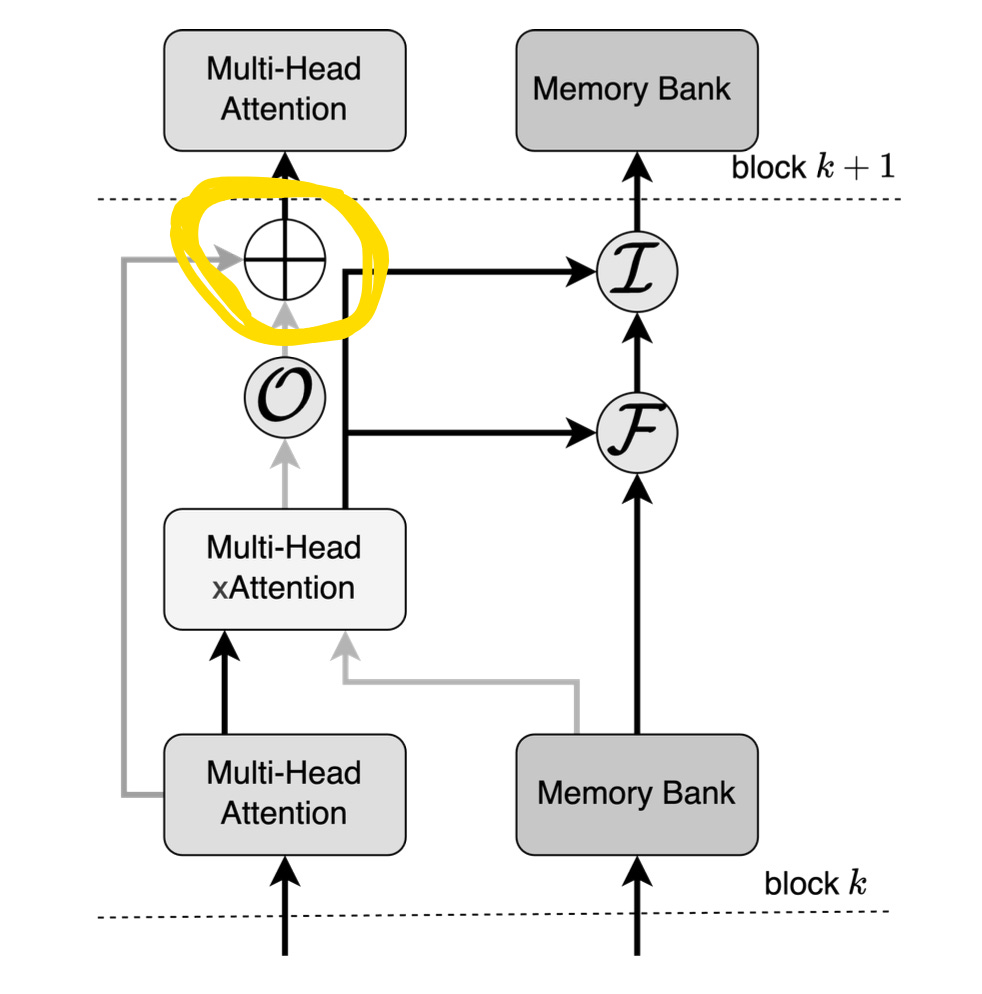
from the below diagram if we focus on selected area
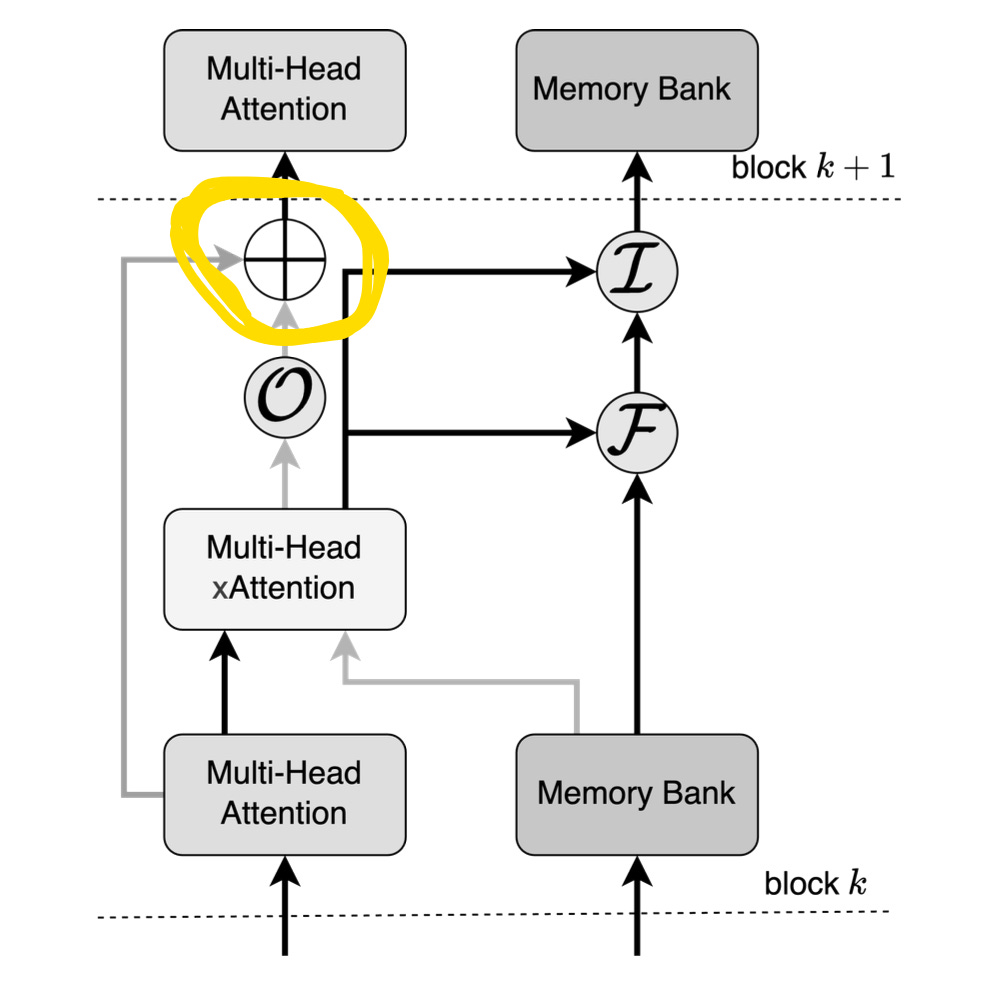
So, focusing of the attention is being updated between heads, The below equation shows the mathematical calculation of it
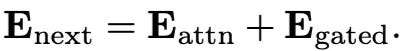
The Attention scores to the next layer (attention) will be current attention scores + gated attention scores, The below 2 equations explains how the Attention scores of gated are being calculated.
Here the E_attn is the regular attention calculation and E_gated is the new addition of attention scores of the gated
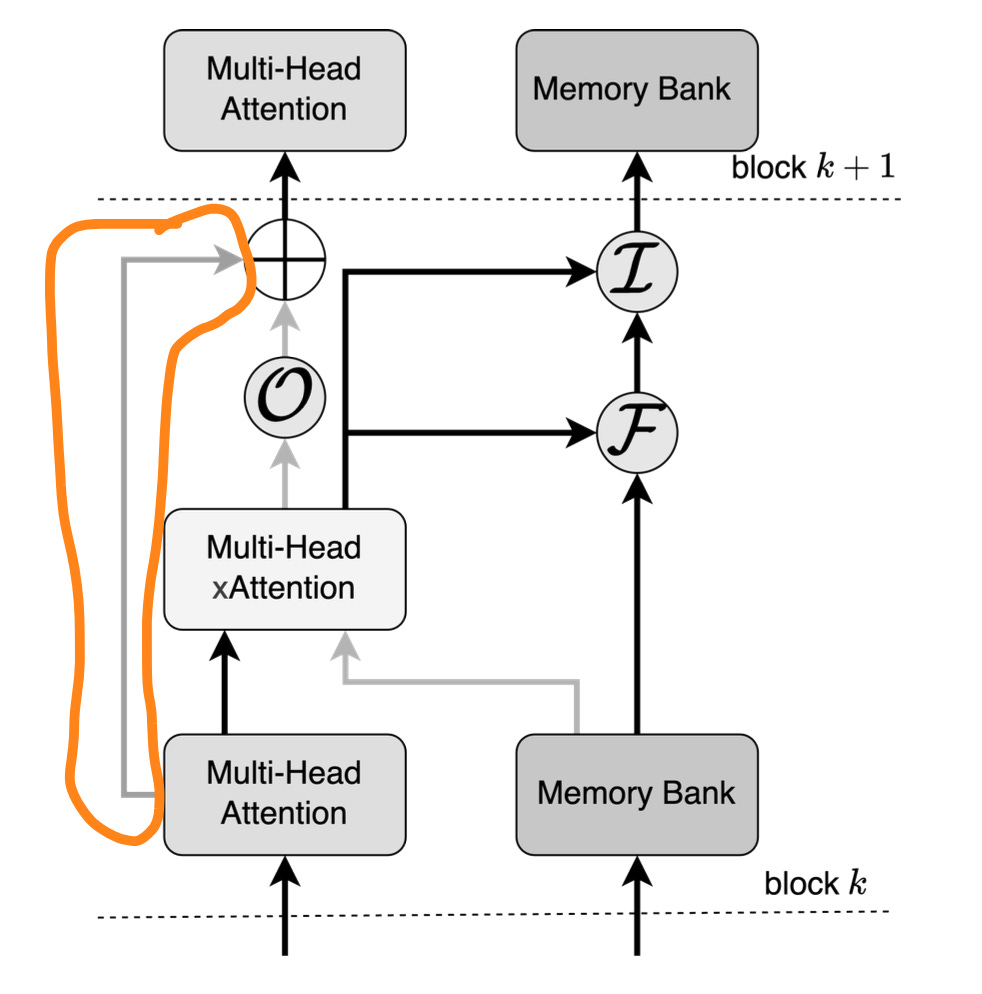
The E_attention is passed as we have a skip through connection (check the below diagram) (highlighted part)
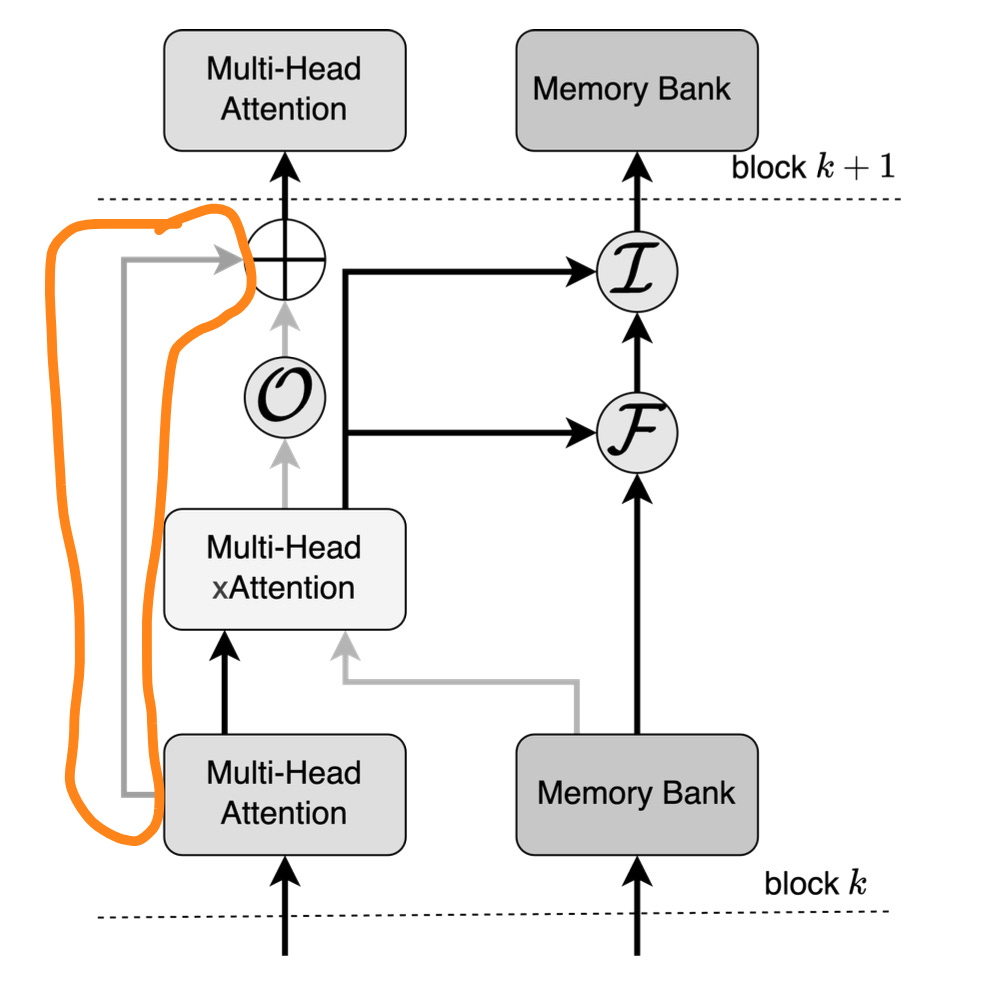
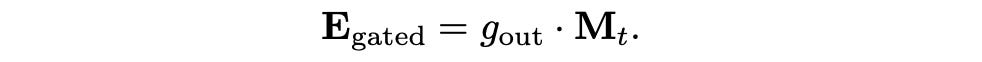
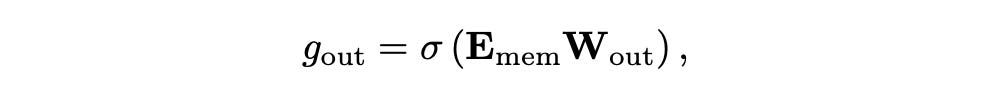
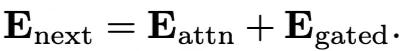
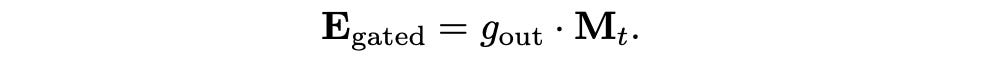
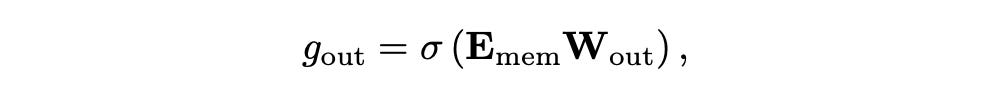
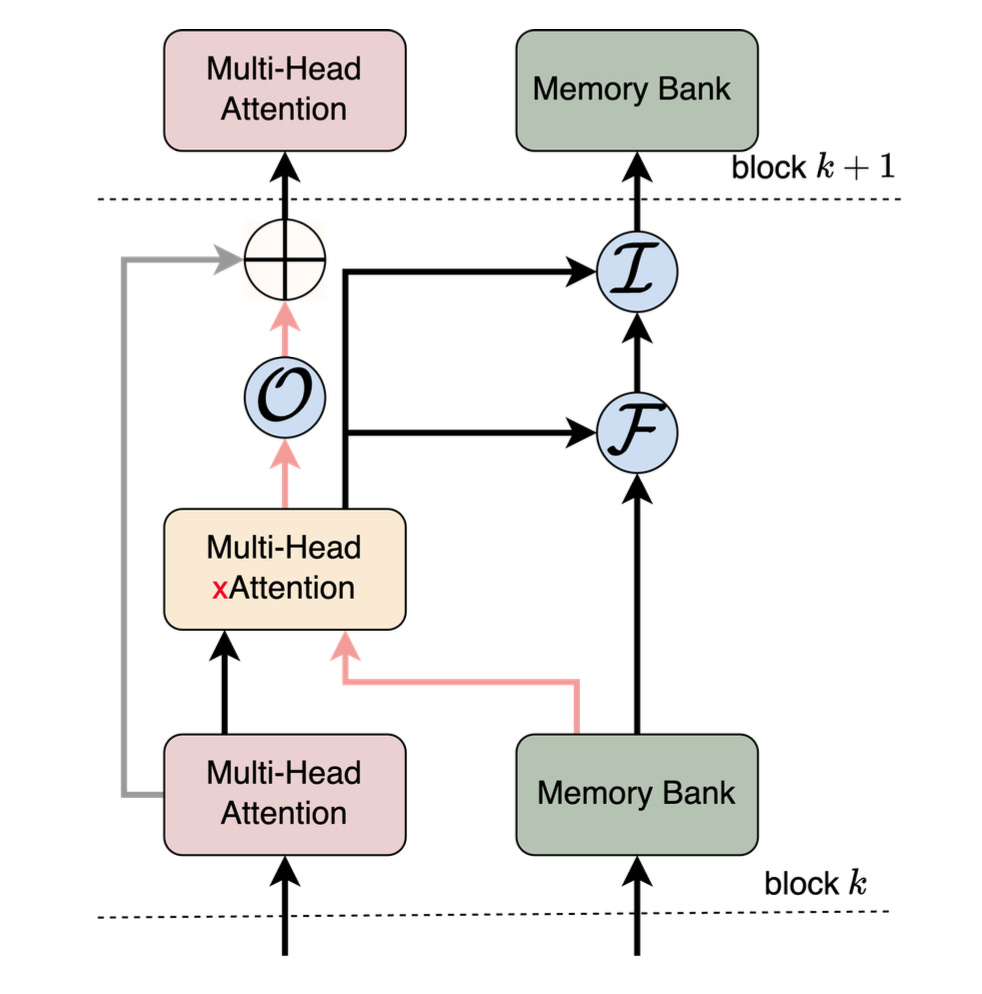
Stage 2: Memory Update
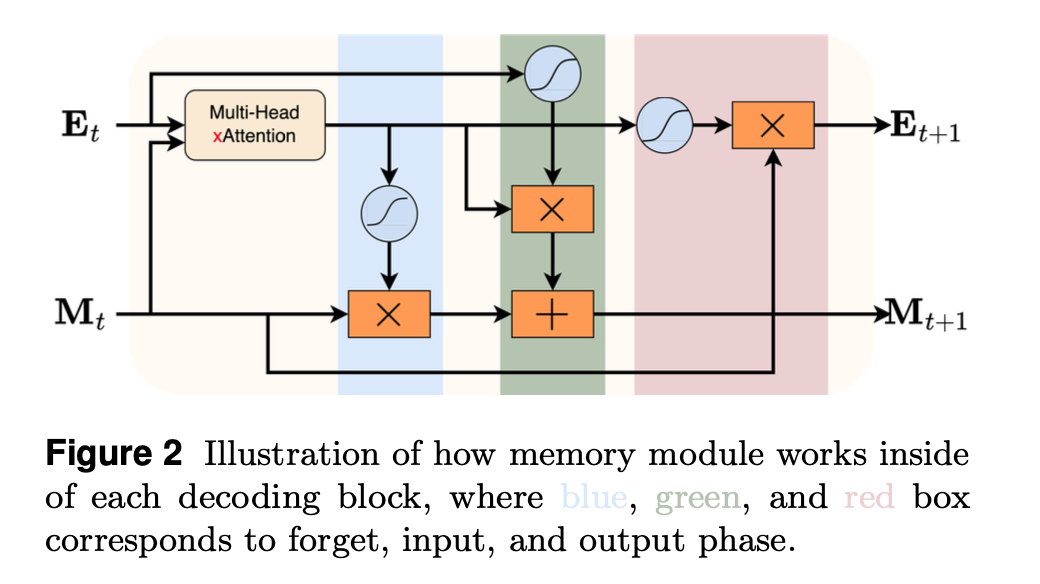
The memory update has 3 gate:
Output, input and forget
This is where we draw comparison with the LSTM as LSTM has similar arch (forget, input and output gates and memory updates)
Here M_t is the Memory and E_t is the attention scores
The below equations are how gating works and memory gets updated
Input gate:
The model decides how much of the newly computed embeddings (E_mem) to incorporate into the memory

Forgetting Phase: Once new information is made available during the input phase, the memory must also decide which parts of its existing content to discard. This is governed by the forget gate
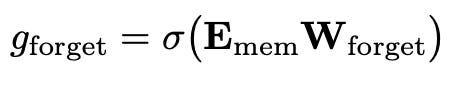
Memory Update: Combining these two gating mechanisms leads to the updated memory state
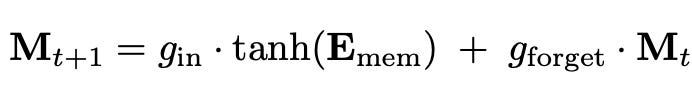
Incorporation of Memory to Transformer Arch
They’ve used decoder part from the transformer and
having 16 decoder blocks each with a dimension of 2048
Feed forward network dimension size being 8192
Their Model has 32 attention heads
Memory bank:
each memory bank has 2048 slots and each slot is of dimension (2048*2048)
Each memory bank is added to each of the 16 decoder blocks (16 memory banks)
Performance results
As already mentioned this model arch is good at handling long context windows
Also performed better in:
Multi Hop Inference:
think of multi hop inference as drawing to final answer in steps rather directly
Multi-hop inference is like solving a puzzle where you need multiple clues. Example: To answer 'What's John's dog's name?', you might need to know: 1. John has a pet 2. John's pet is a dog 3. The dog's name is Spot You combine these facts to reach the answer: Spot.
Previous works
Apart from LMM before this the other way of handling long context reasoning were use of Recurrent Prompts
Recurrent prompts
This is like giving the AI a short note to remember important things. For example, imagine reading a long story and writing down key points on sticky notes. These notes (prompts) are passed from one part of the AI to the next, helping it remember important information.
Example: While reading a story about a family vacation, the AI might create prompts like "Family of 4" or "Visiting Hawaii" to help it remember key details.
1. Summarizing previous answers:
This means the AI takes its previous responses and makes them shorter, using these summaries as new prompts. However, this method doesn't fully handle very long texts.
Example: Imagine answering questions about a 100-page book. After each question, the AI might summarize its answer in a sentence. For the next question, it uses this summary instead of rereading the whole book. This works for some questions but might miss details from the original long text.But, this suffers from maintaining long context reasoning.
Thanks for reading till end :)
References:
paper link and (formula screenshots): https://arxiv.org/pdf/2502.06049
LSTM arch image taken from: https://en.wikipedia.org/wiki/Long_short-term_memory