
Decoding deepseek V3
Disclaimer: This article is not about comparing DeepSeek with other LLM models. Instead, it focuses purely on the concepts involved in it.

Just as transformers by Google revolutionized AI by introducing the concept of attention, DeepSeek is also inspired by the transformer architecture. Let's dive into the key aspects of DeepSeek-V3, breaking it down into data preparation, model architecture, pre-training, token extension, and post-training.
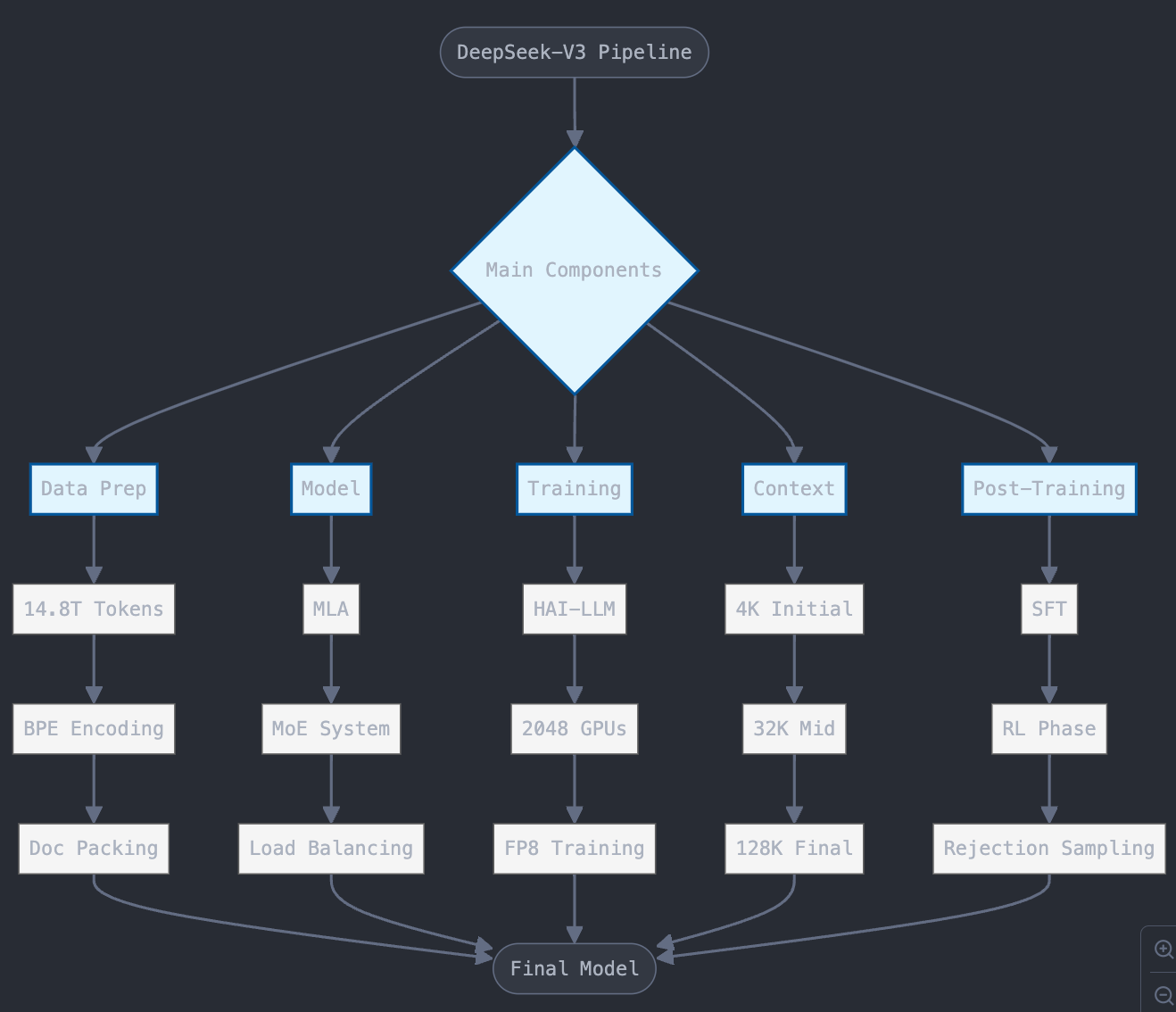
Data Preparation
For any model to perform well, data is crucial:
- They trained on a massive 14.8 trillion tokens, which is a big step up from earlier versions.
- For pre-processing, they used Byte-Pair encoding with an initial token length of 4K.
- They followed document packing (combining multiple small documents into a single one).
- Cross-sample attention was not used, meaning no attention was applied between different data samples.
- Punctuations like ".\n" were handled as two separate strings: "." and "\n".
- Both token embeddings and positional embeddings were used.
Model Architecture
The heart of DeepSeek's network lies in the changes made to the transformer block, particularly the use of MLA and MoE.
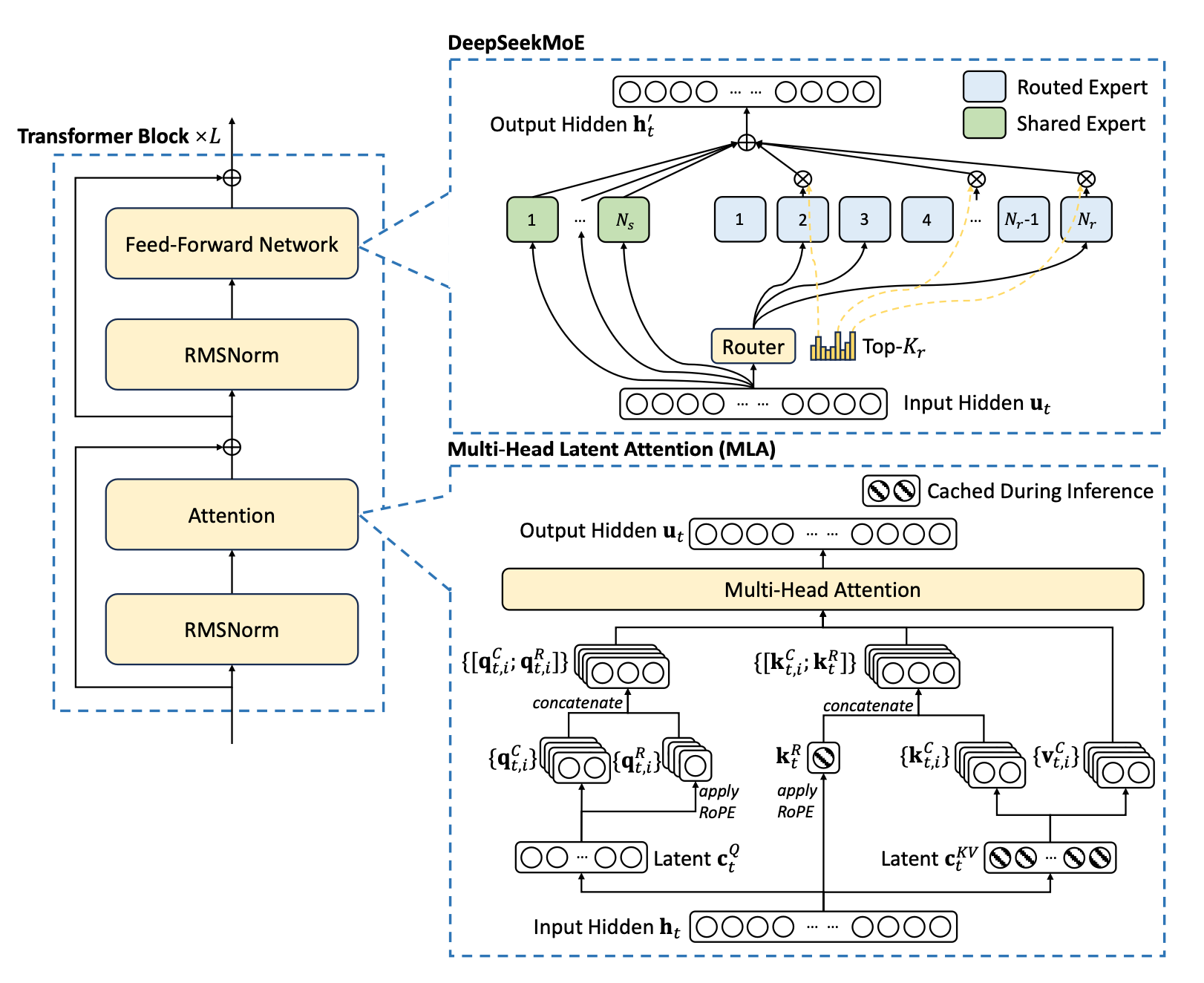
MLA: Multi-head Latent Attention
To explain this simply:
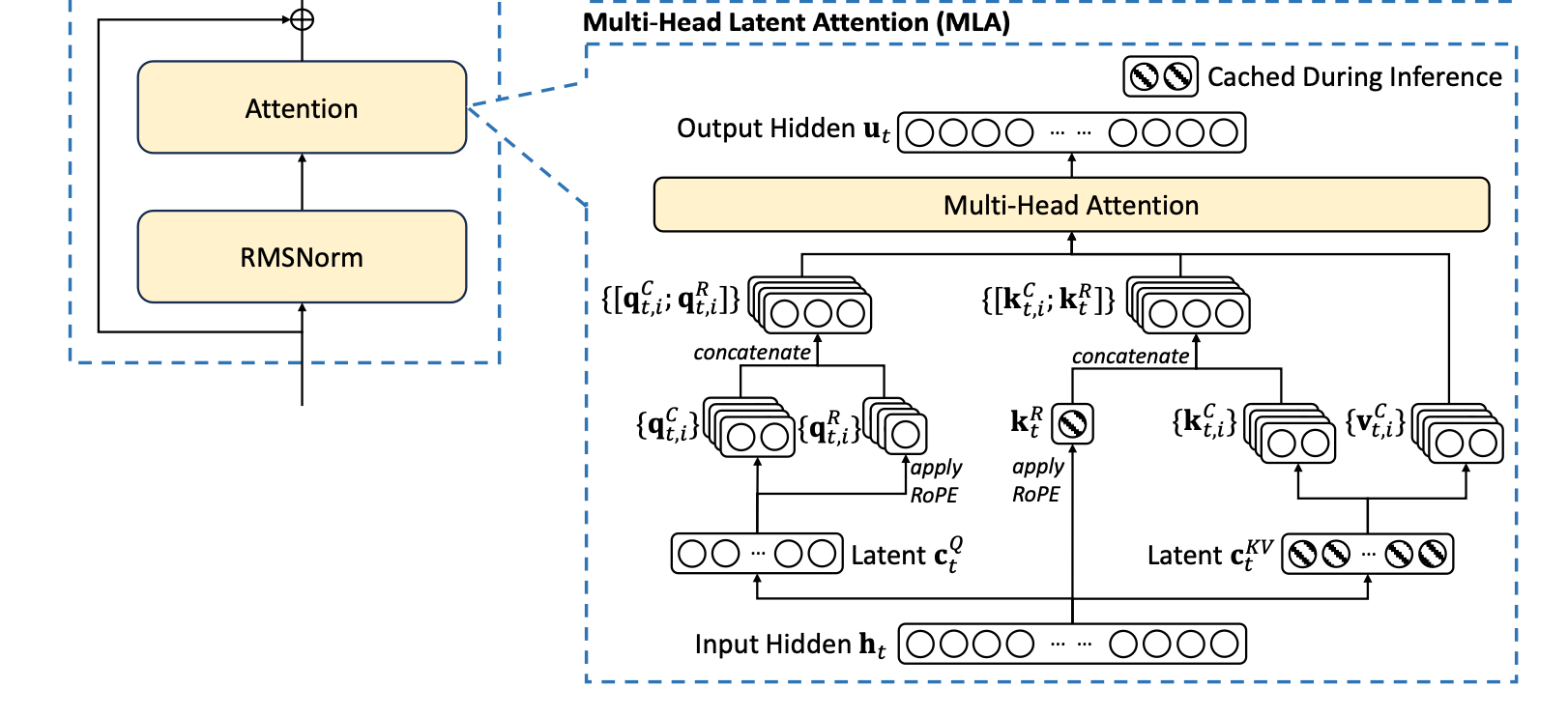
1. K-V pairs are compressed (acting as a summary).
2. Decoupled K (taking only K) is combined with ROPE (rotational position embeddings), acting like a pointer.
With a summary and pointer, applying attention becomes easier.
MoE: Mixture of Experts
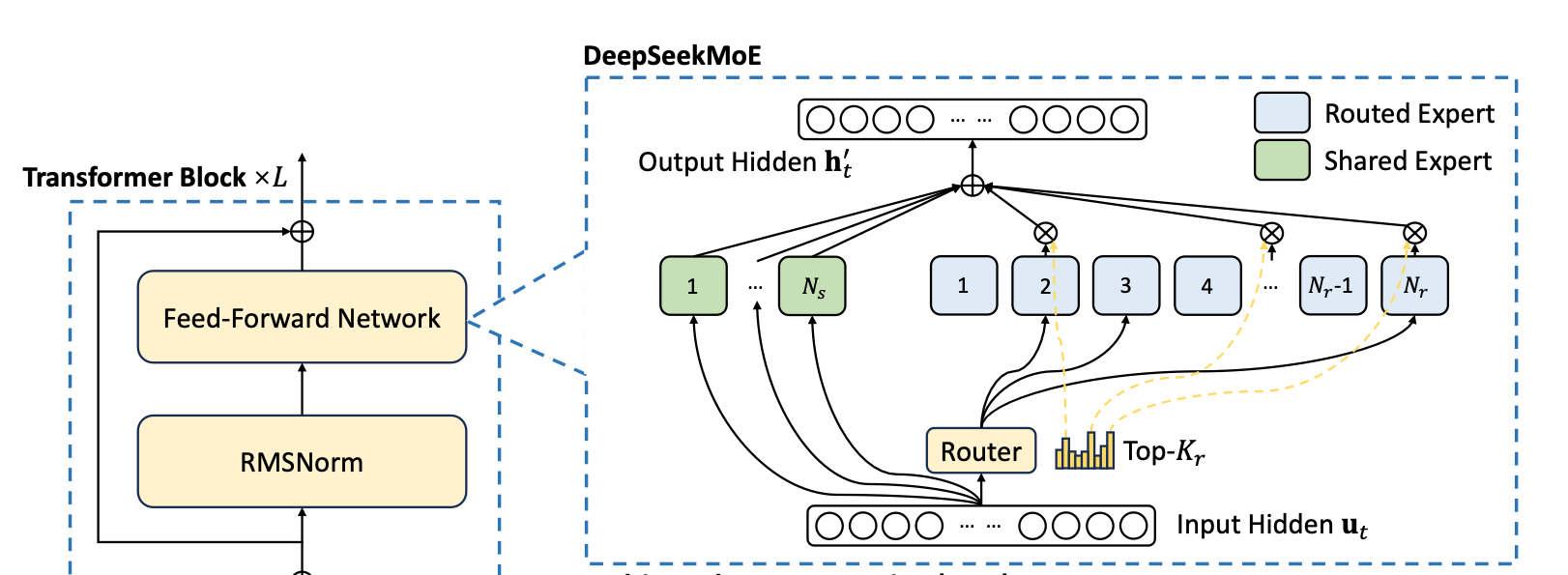
MoE is applied in the feedforward network of the transformer architecture. Instead of a single neural network, it splits the load among small workers (think of it like an agentive workforce).
- DeepSeek-V3 uses a fine-grained MoE.
- The total parameter count is a whopping 671B, with 37B activated for each token.
How is the task distributed? A router takes care of it.
There are two types of experts (workers):
1. Shared workers: Active continuously, handling smaller tasks like grammar correction.
2. Rated workers: Responsible for domain-based tasks (health, finance, etc.) and only active when required.
Load balancing is achieved through an auxiliary loss-free method based on bias (because auxiliary loss creates new gradients and increases computation so they used bias) . They loaded data batch-wise rather than sequence-wise for better load distribution.
Token Prediction
DeepSeek-V3 incorporates a Multi-Token Prediction (MTP) objective. Instead of predicting a single token, it can predict multiple tokens at once using a sequential method. This densifies training signals and could enable faster inference through speculative decoding.
Training Framework
Even though they didn't have the fanciest GPUs, DeepSeek engineered new ways to make use of medium-level GPUs:
- They used 2,048 NVIDIA H800 GPUs for training.
- Developed a custom training framework called HAI-LLM.
- Used FP8 mixed precision training for better efficiency. (instead of focusing on 32 bit floating points it focuses on 8 bits)
- Employed parallelism strategies: multiple model copies trained on different batches in parallel.
- Expert parallelism: MoE splitting among GPUs.
They also implemented a Dual Pipeline algorithm. When work is sent sequentially from GPU1 to GPU2, instead of keeping GPU1 idle while GPU2 works, the dual pipeline ensures GPU1 works on other tasks like preparing data to send to GPU2.

Context Length Extension
Starting with 4K tokens, they extended the context length to 128K:
4K → 32K → 128K
To handle long context understanding beyond ROPE's 4096 limit, they used YARN (Yet another RoPE extension) to scale ROPE embeddings.
Post-Training Process
After the initial pre-training, DeepSeek-V3 undergoes a sophisticated post-training process to enhance its capabilities and align it with human preferences. This process involves several stages:
Supervised Fine-Tuning (SFT)
The SFT stage uses a carefully curated dataset, divided into two main categories:
1. Reasoning Data
- Generated using an expert model based on DeepSeek-R1
Expert Model as Data Generator
The expert model, trained with SFT and RL, generates two types of SFT samples for each instance:
1. Original Format: <problem, original response>
2. Enhanced Format: <system prompt, problem, R1 response>
For example, given a math problem:
Problem: "What is the area of a circle with radius 5 cm?"
1. Original Format:
Problem: What is the area of a circle with radius 5 cm?
Original Response: The area of a circle is calculated using the formula A = πr². With a radius of 5 cm, the area would be A = π(5²) = 25π cm² ≈ 78.54 cm².
2. Enhanced Format:
System Prompt: Provide a step-by-step solution with reflection and verification.
Problem: What is the area of a circle with radius 5 cm?
R1 Response:
Let's approach this step-by-step:
1. Recall the formula for the area of a circle: A = πr²
2. We're given that the radius is 5 cm
3. Let's substitute this into our formula: A = π(5²)
4. Simplify: A = 25π cm²
5. Using π ≈ 3.14159, we get: A ≈ 78.54 cm²
Reflection: This seems reasonable as the area should be larger than the square of the diameter (10² = 100 cm²) but smaller than the square that would contain the circle (10 x 10 = 100 cm²).
Verification: Let's double-check by calculating the circumference (C = 2πr) and comparing:
C = 2π(5) ≈ 31.42 cm
This is indeed the perimeter of a shape with an area of about 78.54 cm², confirming our calculation.
- Addresses issues like overthinking, poor formatting, and excessive length
- Developed using a combined SFT and RL pipeline
- Focuses on domains like coding, mathematics, and logical reasoning
2. Non-Reasoning Data
- Utilizes DeepSeek-V2.5 pipeline
- Verified by human annotators for accuracy
- Covers tasks like writing, factual QA, self-cognition, and translation.
Reinforcement Learning (RL)
The RL phase further refines the model's capabilities:
1. High-temperature sampling: Generates responses incorporating patterns from both R1-generated and original data.
2. Reward Models (RM):
- Rule-Based RM: Used for tasks with deterministic answers (math, coding).
- Model-Based RM: Employed for tasks without definitive answers (creative writing).
3. Language consistency reward: Introduced to mitigate language mixing issues.
During RL it follows GRPO (group related policy optimization)
GRPO: is a training method used to improve the AI model itself. Instead of just picking the best response, it uses all the responses in a group to teach the model which types of answers are better and why.
Example:
Question: "What’s the capital of France?"
AI generates:
Response 1: "Paris" (score: 9)
Response 2: "London" (score: 3)
Response 3: "Berlin" (score: 2)
Instead of just picking "Paris," GRPO teaches the model why "Paris" is better than "London" and "Berlin." It also ensures that the model doesn’t overfit by balancing changes with KL divergence regularization.
After the RL phase converges, rejection sampling is used to curate high-quality SFT data:
Rejection Sampling
1. Generate multiple responses for each problem using the expert model.
2. Evaluate responses based on accuracy, conciseness, and effectiveness.
3. Select the best responses for the final SFT dataset.
Think of rejection sampling like finding a blue sedan in a parking lot: first, you find all the blue cars, then filter for sedans among them.
